1) Predicting US House Prices
Link to the data: https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data
-
I built and trained a regression model to predict the sale price (conitnuous value) of US homes based on many input features.
-
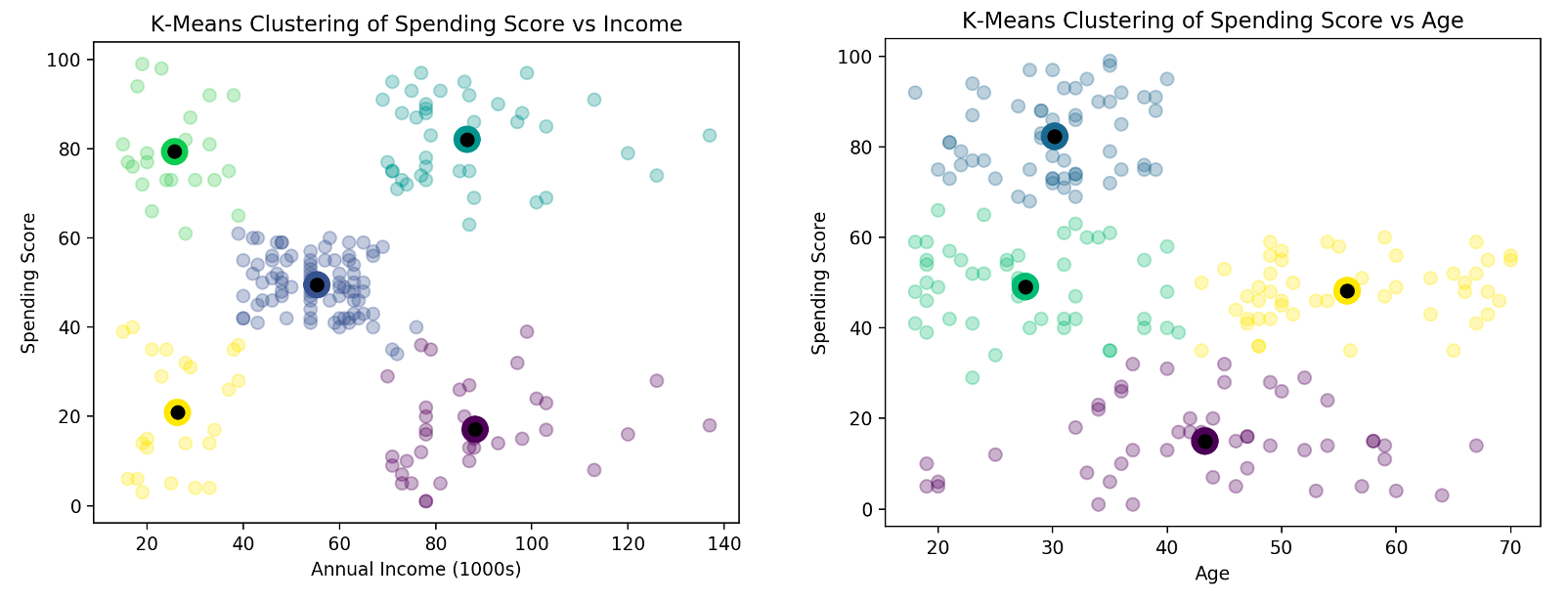
I carried out extensive data exploration and visualisation and I identified the 10 best predictors of sale price and paid special attention to these features for improved performance.
-
I compared several different regressors (SVR, Random Forest, DTR, XGBoost) and found that XGBoost achieved the best performance
-
My model achieved an Root Mean Squared Error (RMSE) of 0.13, placing my predictions in the top 39% of all Kaggle submissions for this task. I will continue to improve my solution over time and move up the leaderboard.
2) Predicting Movie Quality (improvements in progress)
Link to the data: https://www.kaggle.com/carolzhangdc/imdb-5000-movie-dataset
-
This is a classification task in which I built and trained a model to classify if a movie is terrible, bad, good or excellent based on many input features.
-
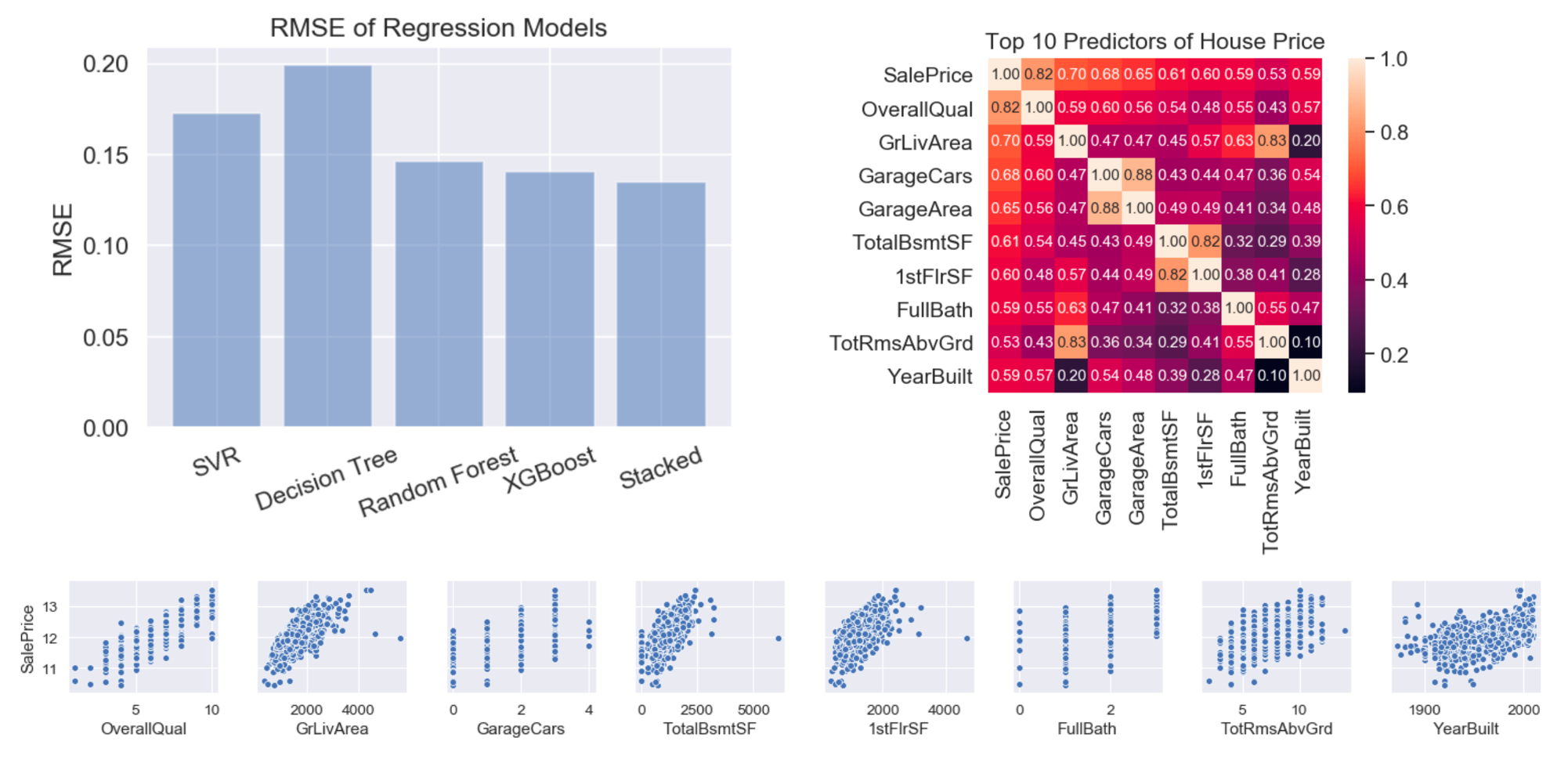
I compared several classification models (Naive Bayes, K-Nearest Neighbours, Support Vector Machine, Random Forest, XGBoost and a Neural Network) and evaluated each via 10-fold cross validation, using accuracy as a metric.
-
The best performaing model was the Random Forest model, with an average F1 score of 69%.
3) Mall Customer Clustering
Link to the data: https://www.kaggle.com/vjchoudhary7/customer-segmentation-tutorial-in-python
-
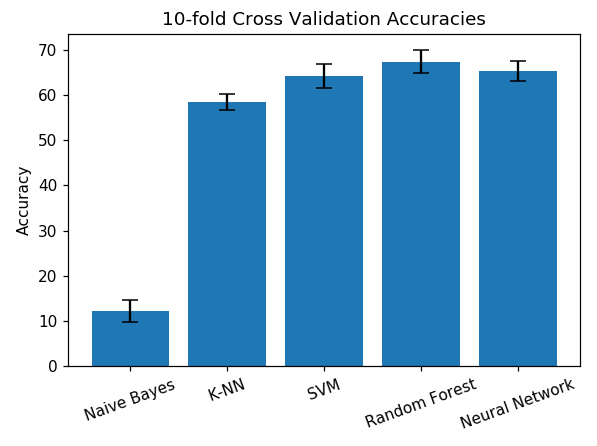
In this task, I wanted to find the best way to split up the shoppers at a mall into distinct groups, based on their age, income and spending behaviour
-
I found that the best way to divide up the customers is by income and spending behaviour, identifying 5 distinct clusters
-
This information could be used to understand the mall shoppers better and to drive research into what kind of offers each group would be most likely to engage with